マイケル
みなさんこんにちは!
マイケルです!
マイケルです!
エレキベア
こんにちクマ〜〜〜
マイケル
今日は引き続きオセロAI開発を進めていきます!
これまでMiniMax法、モンテカルロ法と作ってきたけど、
今回はML-Agentsを使った強化学習に挑戦してみます!!
これまでMiniMax法、モンテカルロ法と作ってきたけど、
今回はML-Agentsを使った強化学習に挑戦してみます!!



↑前回までの記事
エレキベア
ついに機械学習に手を出すクマね
マイケル
AI同士を対戦させながら強くしていく「セルフプレイ学習」
という手法を使って学習させてみようと思っているよ!
ML-Agentsとセルフプレイ学習について知りたい方は、下記記事をご覧ください!!
という手法を使って学習させてみようと思っているよ!
ML-Agentsとセルフプレイ学習について知りたい方は、下記記事をご覧ください!!


↑今回に向けて習得しておきました
エレキベア
対戦させながら相手もどんどん強くなっていくやつクマね
オセロだと上手くいくのか楽しみクマ〜〜〜〜
オセロだと上手くいくのか楽しみクマ〜〜〜〜
参考書籍
マイケル
AI作成を進めるにあたり、ML-Agents、セルフプレイ学習の概要を知るため、
公式リポジトリと下記書籍を参考にさせていただきました!
公式リポジトリと下記書籍を参考にさせていただきました!
[公式リポジトリ]
Unity-Technologies/ml-agents – Reference (Release19)

Unity ML-Agents 実践ゲームプログラミング v1.1対応版
エレキベア
書籍も分かりやすかったからおすすめクマ〜〜〜
学習スクリプトの作成
マイケル
それでは早速学習スクリプトを作成します!
前回までのオセロゲームに組み込む形で作成していて、GitHubにも公開しているので
詳細はこちらをご覧ください!!
前回までのオセロゲームに組み込む形で作成していて、GitHubにも公開しているので
詳細はこちらをご覧ください!!
GitHub – masarito617/unity-reversi-game-scripts#v0.3.0
エレキベア
上手く組み込めたらいいクマね
マイケル
なお、今回使用したバージョンは下記の通りです!
紹介する情報は古くなっていく可能性もあるため、ご了承ください!
紹介する情報は古くなっていく可能性もあるため、ご了承ください!
| バージョン | |
| Unity | 2021.3.1f1 |
| ML-Agents | Release19 |
| Python | 3.7.10 |
↑今回使用したバージョン
エレキベア
Pythonは3.6、3.7が推奨されていたクマね
ゲームの事前準備
マイケル
まずはこのゲーム特有になりますが、
学習させるために行った事前準備について記載しておきます!
学習させるために行った事前準備について記載しておきます!
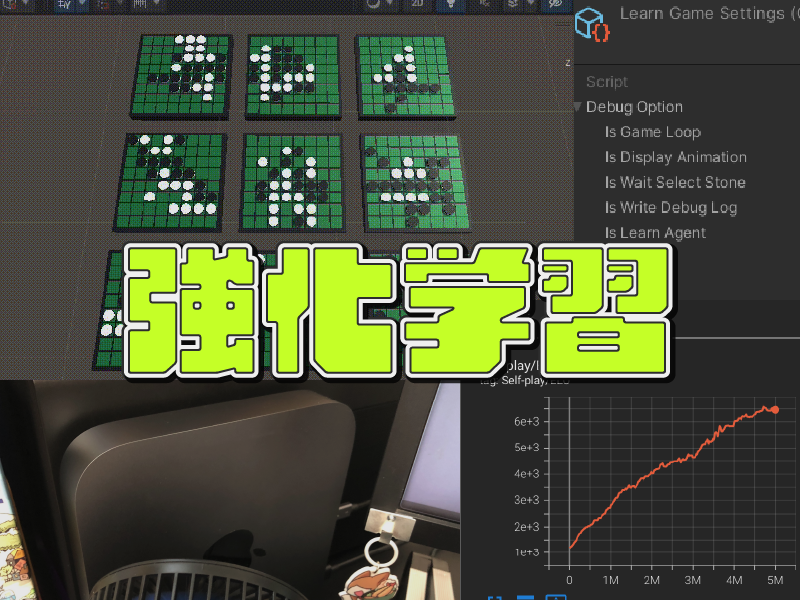
学習用のデバッグ設定
マイケル
一つ目の準備として、ゲーム実行のオプションを
ScriptableObjectで指定できるようにしました。
ScriptableObjectで指定できるようにしました。
GitHub – masarito617/unity-reversi-game-scripts#v0.3.0 – GameSettings.cs
マイケル
こちらを学習用の設定として
・ゲームをループする
・アニメーションを表示しない
と指定して高速でゲームをプレイできるようにしておきます。
・ゲームをループする
・アニメーションを表示しない
と指定して高速でゲームをプレイできるようにしておきます。
エレキベア
見ていて気持ちがいいクマね
マイケル
ちなみに学習用のプレイヤーについては下記のように
Prefabを読み込んでプレイヤークラスに設定するようにしました。
Prefabを読み込んでプレイヤークラスに設定するようにしました。
/// <summary>
/// プレイヤー作成処理
/// </summary>
/// <param name="playerType">プレイヤータイプ</param>
/// <param name="stoneState">プレイヤーの石の色</param>
/// <param name="putStoneAction">ストーンを置く処理</param>
/// <returns>作成したプレイヤー</returns>
public IPlayer CreatePlayer(PlayerType playerType, StoneState stoneState, Action<StoneState, int, int> putStoneAction)
{
IPlayer player = null;
switch (playerType)
{
・・・略・・・
// Prefabを読み込んで設定
case PlayerType.MlAgentAIPlayerLearn1:
player = new MlAgentsAIPlayer(stoneState, putStoneAction);
player.OnInstantiate(_assetsService.LoadAssets("Player/MLAgentAIPlayerLearn1"));
break;
case PlayerType.MlAgentAIPlayerLearn2:
player = new MlAgentsAIPlayer(stoneState, putStoneAction);
player.OnInstantiate(_assetsService.LoadAssets("Player/MLAgentAIPlayerLearn2"));
break;
}
return player;
}
学習用シーンの作成
マイケル
あとは学習用のシーンを作成して、作ったデバッグ設定を読み込むようにしておきます。
また、学習を効率化するため下記のようにボードを複数配置しました。
また、学習を効率化するため下記のようにボードを複数配置しました。
マイケル
今回はVContainerを使用しているため、
少々無理矢理ですがLifeTimeScopeごと複製して配置しています。
また、UIも合わせて非表示にしました。
少々無理矢理ですがLifeTimeScopeごと複製して配置しています。
また、UIも合わせて非表示にしました。
エレキベア
管理クラスも平行で複数動いているイメージクマね
マイケル
以上でゲーム側の準備は完了です!
学習用の処理を書いていきましょう!
学習用の処理を書いていきましょう!
学習全体の概要
マイケル
まず学習全体の概要について説明します。
前提知識として、ML-Agentsの強化学習サイクルは下記のようになっています。
前提知識として、ML-Agentsの強化学習サイクルは下記のようになっています。
↑学習のサイクル
エレキベア
状態を観察して行動、その結果に応じて報酬を受け取るだったクマね
マイケル
そして今回行うオセロAIの学習については
下記のように設定しています。
下記のように設定しています。
状態取得:
盤面の状態(8×8=64の状態配列)
行動:
置くマスの位置(0〜63)
報酬取得:
勝ったら1.0、負けたら-1.0
マイケル
盤面の状態を観察して置くのを繰り返して、
最終的なゲーム結果で報酬を設定しています。
最終的なゲーム結果で報酬を設定しています。
エレキベア
シンプルな学習内容クマ
マイケル
そのためBehaviour Parametersの設定としては下記のようになります。
置くマスのインデックスは連続していないため、離散値(Discrete)として64種類の中から選ぶように指定します。
置くマスのインデックスは連続していないため、離散値(Discrete)として64種類の中から選ぶように指定します。
エレキベア
それぞれのマスは独立しているからクマね
マイケル
あとはセルフプレイで学習させるため、
対戦相手のTeamIdは異なる値で設定しておきます。
対戦相手のTeamIdは異なる値で設定しておきます。
マイケル
以上が学習全体の概要になります!
これから学習スクリプトの内容の要所ごとに見ていきますが、全体が見たい方は下記をご参照ください!
これから学習スクリプトの内容の要所ごとに見ていきますが、全体が見たい方は下記をご参照ください!
GitHub – masarito617/unity-reversi-game-scripts#v0.3.0 – ReversiAIAgent.cs
エレキベア
長いから全部は載せられないクマね
決定の要求開始
マイケル
エージェントに任意のタイミングで決定を要求するため、
自分のターンになったタイミングでRequestDecision関数を呼び出すようにします。
該当処理は下記で、ボードの状態や置けるマスについてもこの時受け取るようにしています。
自分のターンになったタイミングでRequestDecision関数を呼び出すようにします。
該当処理は下記で、ボードの状態や置けるマスについてもこの時受け取るようにしています。
/// <summary>
/// ストーン情報
/// </summary>
private StoneState[,] _stoneStates;
private StoneIndex[] _canPutStoneIndices;
private StoneState _myStoneState;
private StoneIndex _selectStoneIndex;
/// <summary>
/// ストーン探索処理
/// </summary>
/// <param name="stoneStates">ストーン状態配列</param>
/// <param name="canPutStoneIndices">置けるマスのインデックス配列</param>
/// <param name="myStoneState">自分のストーンの色</param>
/// <returns>探索結果(置くインデックス)</returns>
public async UniTask<StoneIndex> OnSearchSelectStone(StoneState[,] stoneStates, StoneIndex[] canPutStoneIndices, StoneState myStoneState)
{
// ストーン状態を設定
_stoneStates = stoneStates;
_canPutStoneIndices = canPutStoneIndices;
_myStoneState = myStoneState;
_selectStoneIndex = null;
// 決定を要求する
RequestDecision();
// 置く位置を探索したら返却する
await UniTask.WaitWhile(() => _selectStoneIndex == null);
return _selectStoneIndex;
}
マイケル
エージェントクラスに関してはPlayerクラス内に持たせて、
自分のターンになったら呼び出すようにしています。
自分のターンになったら呼び出すようにしています。
using System;
using Reversi.Managers;
using Reversi.Players.Agents;
using Reversi.Stones;
using Reversi.Stones.Stone;
namespace Reversi.Players.AI
{
/// <summary>
/// MLAgentsを使用したAI
/// </summary>
public class MlAgentsAIPlayer : Player
{
private ReversiAIAgent _agent;
public MlAgentsAIPlayer(StoneState myStoneState, Action<StoneState, int, int> putStoneAction) : base(myStoneState, putStoneAction) { }
protected override void StartThink()
{
// エージェントクラスを取得
if (_agent == null && PlayerGameObject != null)
{
_agent = PlayerGameObject.GetComponent<ReversiAIAgent>();
}
// 思考開始
StartThinkAsync();
}
/// <summary>
/// 選択するストーンを考える
/// </summary>
private async void StartThinkAsync()
{
// 考える時間
await WaitSelectTime(200);
// ストーン探索処理
var canPutStones = StoneCalculator.GetAllCanPutStonesIndex(StoneStates, MyStoneState);
SelectStoneIndex = await _agent.OnSearchSelectStone(StoneStates, canPutStones.ToArray(), MyStoneState);
}
protected override void EndGame(PlayerResultState resultState)
{
// ゲームを終了させる
_agent.OnGameEnd(resultState);
}
}
}
エレキベア
あくまでゲーム側から制御するクマね
状態の取得
マイケル
観察値の状態についてはボード状態をfloat配列に変換して設定するだけですが、
自分の石の色に限らず動作するようにしたいので、石の色に応じて値を反転するようにしています。
自分の石の色に限らず動作するようにしたいので、石の色に応じて値を反転するようにしています。
/// <summary>
/// 観察
/// </summary>
public override void CollectObservations(VectorSensor sensor)
{
var learnStoneStates = ConvertLearnStoneStates(_stoneStates, _myStoneState);
sensor.AddObservation(learnStoneStates);
}
/// <summary>
/// ストーン状態配列を学習形式に変換して返却する
/// </summary>
private float[] ConvertLearnStoneStates(StoneState[,] stoneStates, StoneState myStoneState)
{
var convStoneStates = new float[stoneStates.Length];
for (var i = 0; i < stoneStates.Length; i++)
{
var x = i % stoneStates.GetLength(0);
var z = i / stoneStates.GetLength(0);
convStoneStates[i] = ConvertLearnStoneState(stoneStates[x, z], myStoneState);
}
return convStoneStates;
}
/// <summary>
/// ストーン状態を学習形式に変換して返却する
/// </summary>
private float ConvertLearnStoneState(StoneState stoneState, StoneState myStoneState)
{
// 何も置いてない:0
if (stoneState == StoneState.Empty) return 0.0f;
// 自分の色:1、相手の色:2
return stoneState == myStoneState ? 1.0f : 2.0f;
}
エレキベア
観察値の状態は合わせておかないといけないクマね
行動
マイケル
行動については、置けないマスをWriteDiscreteActionMask関数でマスクしておくことで、
置けるマスの中からのみ選択できるようにしておきます。
置けるマスの中からのみ選択できるようにしておきます。
/// <summary>
/// 行動
/// </summary>
public override void OnActionReceived(ActionBuffers actions)
{
// ストーンを置く
var discreteActions = actions.DiscreteActions;
var index = discreteActions[0];
var x = index % _stoneStates.GetLength(0);
var z = index / _stoneStates.GetLength(0);
var selectIndex = new StoneIndex(x, z);
// 何故かマスクが効かないことがあったので、置ける場所かどうかのチェックを行う
var isExist = false;
foreach (var canPutStoneIndex in _canPutStoneIndices)
{
if (canPutStoneIndex.Equals(selectIndex)) isExist = true;
}
// 置けない場所に置こうとしたら再度行動をリクエスト
if (!isExist)
{
RequestDecision();
return;
}
_selectStoneIndex = selectIndex;
}
/// <summary>
/// 行動のマスク
/// </summary>
public override void WriteDiscreteActionMask(IDiscreteActionMask actionMask)
{
// 置くことが可能なストーンを調べる
for (var i = 0; i < _stoneStates.Length; i++)
{
var x = i % _stoneStates.GetLength(0);
var z = i / _stoneStates.GetLength(0);
var isCanPutStone = false;
foreach (var canPutStoneIndex in _canPutStoneIndices)
{
if (x == canPutStoneIndex.X && z == canPutStoneIndex.Z)
{
isCanPutStone = true;
}
}
// 置くことが可能なストーンのみ活性にする
actionMask.SetActionEnabled(0, i, isCanPutStone);
}
}
マイケル
但し、自分の実装が悪いのかバグなのか分かりませんが
ごく稀にマスクが効かないことがあったので、置けない場所が選択された場合には再度決定を要求するようにしました。
ごく稀にマスクが効かないことがあったので、置けない場所が選択された場合には再度決定を要求するようにしました。
エレキベア
それは何だか気持ちが悪いクマ・・・
報酬取得
マイケル
最後は報酬の設定です。
こちらはゲームの結果に応じて1.0、-1.0を設定するだけです。
こちらはゲームの結果に応じて1.0、-1.0を設定するだけです。
/// <summary>
/// ゲーム終了処理
/// </summary>
/// <param name="resultState">勝敗結果</param>
public void OnGameEnd(PlayerResultState resultState)
{
// 結果に応じて報酬を与える
switch (resultState)
{
case PlayerResultState.Win:
SetReward(1.0f);
break;
case PlayerResultState.Lose:
SetReward(-1.0f);
break;
}
// エピソード終了
EndEpisode();
}
エレキベア
セルフプレイ学習は最終的な結果を
1.0、-1.0に設定しないといけなかったクマね
1.0、-1.0に設定しないといけなかったクマね
ヒューリスティック処理による動作確認
マイケル
最後にヒューリスティック処理についてですが、
こちらは動作確認用と割り切って、置けるマスの中からランダムで選んで設定するようにしました。
こちらは動作確認用と割り切って、置けるマスの中からランダムで選んで設定するようにしました。
/// <summary>
/// ヒューリスティック処理
/// </summary>
/// <param name="actionsOut"></param>
public override void Heuristic(in ActionBuffers actionsOut)
{
// 置けるマスの中からランダムで決定する
var stoneIndex = _canPutStoneIndices[UnityEngine.Random.Range(0, _canPutStoneIndices.Length)];
var index = stoneIndex.Z * _stoneStates.GetLength(0) + stoneIndex.X;
var discreteActions = actionsOut.DiscreteActions;
discreteActions[0] = index;
}
マイケル
ヒューリスティックモードで動かしてゲームが動作することを確認できれば、
大方の実装はOKだと思います!
大方の実装はOKだと思います!
エレキベア
これで学習の一通りの実装ができたクマね
学習実行と対戦結果
強化学習の実行
マイケル
それでは学習を実行してみましょう!
今回は訓練設定ファイルは下記のように指定しました。
今回は訓練設定ファイルは下記のように指定しました。
behaviors:
Reversi:
# トレーナー種別
trainer_type: ppo
# ハイパーパラメータ
hyperparameters:
# PPO、SAC共通
batch_size: 32
buffer_size: 320
learning_rate: 3.0e-4
learning_rate_schedule: constant
# PPO固有
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
# ニューラルネットワーク
network_settings:
normalize: true
hidden_units: 128
num_layers: 2
vis_encode_type: simple
# 報酬シグナル
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
# 基本設定
max_steps: 500000
time_horizon: 1000
summary_freq: 5000
# セルフプレイ
self_play:
save_steps: 10000
team_change: 50000
swap_steps: 10000
play_against_latest_model_ratio: 0.5
window: 10
initial_elo: 1200.0
マイケル
学習開始すると下記のようにすごい勢いでオセロが始まります。
エレキベア
狂気を感じるクマ・・・
マイケル
今回は500000ステップ学習させて、1〜2時間ほどで完了しました。
セルフプレイの学習結果指標であるELOも順調に上昇していることが分かります。
セルフプレイの学習結果指標であるELOも順調に上昇していることが分かります。
エレキベア
これは期待できるクマね
各AIと対戦させてみる
マイケル
学習が完了したところで、他のAIと対戦させてみましょう!
マイケル
果たしてどの程度の強さになったでしょうか?!
各AIと50戦対戦させてみた結果は下記の通りです!!
各AIと50戦対戦させてみた結果は下記の通りです!!
エレキベア
強く育ってくれてるといいクマが・・・
ワクワククマ〜〜〜〜
ワクワククマ〜〜〜〜
| 対戦相手 | 勝ち | 負け | 引き分け |
| ランダムに置くAI | 41 | 7 | 2 |
| MiniMax法AI | 20 | 29 | 1 |
| モンテカルロ法AI | 6 | 44 | 0 |
↑それぞれ50回対戦させてみた結果
マイケル
さすがにランダムに置くAIには勝てるようになりましたが、
MiniMax法やモンテカルロ法といった定番AIには及ばないといった結果になりました。
MiniMax法やモンテカルロ法といった定番AIには及ばないといった結果になりました。
エレキベア
むむむクマ・・・
やはりセルフプレイの強化学習では限界があったクマか・・・
でもMiniMax法のAIとはいい勝負できてるからすごいクマね
やはりセルフプレイの強化学習では限界があったクマか・・・
でもMiniMax法のAIとはいい勝負できてるからすごいクマね
マイケル
ちなみに学習時間が足りないのかな?と思い、
12時間(5000000ステップ)ほど学習させてみたのですが、それでも結果はほぼ変わらずでした・・・。
12時間(5000000ステップ)ほど学習させてみたのですが、それでも結果はほぼ変わらずでした・・・。
エレキベア
たくさん学習させればいいというわけではないのクマね
MiniMaxMonteキラーAIを作る
強化学習の実行
マイケル
これで終わるのもな〜と思ったので、最後の悪あがきとして
現段階で作ったAIの中で一番強い「MiniMax法とモンテカルロ法をミックスしたAI」
を相手に特化したAIを作ってみます!!
現段階で作ったAIの中で一番強い「MiniMax法とモンテカルロ法をミックスしたAI」
を相手に特化したAIを作ってみます!!
マイケル
その名も・・・「MiniMaxMonteキラーAI」です!!
エレキベア
なんかカッコいいクマ・・・
マイケル
やることは簡単で、対戦相手を該当のAIに指定して
ひたすら闘わせて学習させるだけです!
ひたすら闘わせて学習させるだけです!
マイケル
セルフプレイ学習ではなくなるため訓練学習ファイルからセルフプレイ用の設定は削除し、
学習率もlinearに指定して学習実行してみます!
学習率もlinearに指定して学習実行してみます!
behaviors:
Reversi:
# トレーナー種別
trainer_type: ppo
# ハイパーパラメータ
hyperparameters:
# PPO、SAC共通
batch_size: 32
buffer_size: 320
learning_rate: 3.0e-4
learning_rate_schedule: linear # 学習率を上げていく
# PPO固有
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
# ニューラルネットワーク
network_settings:
normalize: true
hidden_units: 128
num_layers: 2
vis_encode_type: simple
# 報酬シグナル
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
# 基本設定
max_steps: 500000
time_horizon: 1000
summary_freq: 5000
マイケル
少し時間はかかりますが、学習させた結果下記のように
順調に学習できていることが確認できました。
後半は平均報酬が「0.7」まで上がっていてかなりの勝率になっていることが分かります。
順調に学習できていることが確認できました。
後半は平均報酬が「0.7」まで上がっていてかなりの勝率になっていることが分かります。
エレキベア
これはもしかしたら・・・
もしかするかもクマ・・・!!
もしかするかもクマ・・・!!
各AIと対戦させてみる
マイケル
さて、このAIと再度闘わせてみた結果はこちら!!
| 対戦相手 | 勝ち | 負け | 引き分け |
| ランダムに置くAI | 32 | 18 | 0 |
| MiniMax法AI | 45 | 5 | 0 |
| モンテカルロ法AI | 1 | 49 | 0 |
↑それぞれ50回対戦させてみた結果
エレキベア
これは・・・
マイケル
MiniMax法AIにはやたら強くなりましたが、
ランダムに置くAIの勝率も下がっていて、モンテカルロ法にはボロ負けという結果になりました。
ランダムに置くAIの勝率も下がっていて、モンテカルロ法にはボロ負けという結果になりました。
マイケル
対戦させたのがMiniMax法主体のAIだったため、偏りがでてしまったのでしょう・・・。
自分も対戦してみたところ、角を簡単に取れるのであまり強くない印象でした。
自分も対戦してみたところ、角を簡単に取れるのであまり強くない印象でした。
エレキベア
固定の相手と対戦させると偏りが出てしまうのクマね・・・
中々難しいクマ〜〜〜〜
中々難しいクマ〜〜〜〜
マイケル
対戦相手をランダムで変えたり、モンテカルロ法のみのAIで学習させてみたりなど
他にも試してみたいこともいくつかありますが、今回はとりあえずここまでにしておきましょう!!
他にも試してみたいこともいくつかありますが、今回はとりあえずここまでにしておきましょう!!
おわりに
マイケル
というわけで今回は強化学習を用いたAIの作成でした!
どうだったかな??
どうだったかな??
エレキベア
強化学習でどこまでできるのか気になっていたクマが、
意外と闘えるレベルまで成長したのが面白かったクマね
意外と闘えるレベルまで成長したのが面白かったクマね
マイケル
中くらいの強さのAIが出来たし、自分で学習して成長する様子は見ていて面白いね!
とりあえず今回の教訓はこんな感じかな!
とりあえず今回の教訓はこんな感じかな!
- 単純な強化学習よりは古典的なAIの方が強い
- 対戦相手を固定で強化学習すると偏ったAIになる
エレキベア
やり方によっては強いAIも作れそうな気がするクマが難しいクマね
マイケル
個人的には深層学習とモンテカルロ法を活用したAlphaZeroという学習方法が強いみたいで気になるんだけど、踏み込みすぎると沼にハマってしまいそうなので
AI作成はとりあえずこの辺にして、今後はオセロゲーム完成に向けて進めていこうと思うよ!
AI作成はとりあえずこの辺にして、今後はオセロゲーム完成に向けて進めていこうと思うよ!
エレキベア
当初の目的も強いAIを作ることじゃなかったクマね
これまで作ったのを組み合わせて面白いオセロが出来るといいクマね
これまで作ったのを組み合わせて面白いオセロが出来るといいクマね
マイケル
長かったけど完成に向けて進めていこう!
とりあえず今日はこの辺で!アデュー!!
とりあえず今日はこの辺で!アデュー!!
エレキベア
クマ〜〜〜〜〜
【Unity】第四回 オセロAI開発 〜ML-Agentsの強化学習を用いたAIの作成〜【ゲームAI】〜完〜
↓次回の記事はこちら!